|
|
|||||||
| Plauderecke Alles, was garantiert nichts mit Physik zu tun hat. Seid nett zueinander! |
 |
|
|
Themen-Optionen | Ansicht |
|
#11
 31.08.10, 03:13
31.08.10, 03:13
|
||||
|
||||
|
Gesamtuebersicht r=2 bis 4
 Sieht doch wirklich gut aus. Mit solch einem Bild haette ich nicht gerechnet. Dargestellte ist das Gauss Guetemass zwischen der deutschen Buchstabenhaeufigkeit und Haufigkeitsklassen einer diskretisierten logistischen (Verhulst) Gleichung. Man muss das Bild so interpretieren. Wenn der Wert auf Null sinkt sind beide Verteilungen gleich ! Klar der Bereich 2 ..3 ist quatsch. Auch der 2 er Zyklus ab 3.0 . Wirklich ? Es gibt kleine Menschen die plappern nur : Mama mama mama oder papa papa papa dada dada lalalala Spaeter dann ein 4 er Zyklus Auto Auto Auto .... Das Bild oben zeigt in der Tat auch eine evolutionaere Entwicklung. Aber egal. Es ist klar. Fuer eine richtige Sprache ist der Bereich zwischen 3.5 und 4 interessant. Ein Problem hab ich noch. Die 36 Klassen hab ich willkuerlich gewaehlt um dem grossen Fenster besser gerecht zu werden. Ich denke ich verwende jetzt doch lieber 27 Klassen. Das muss ich noch genau ueberlegen. Es ist im Grunde ok, denn es ist die schaerfste Forderung. Damit sieht der interessante Bereich wie folgt aus :  Damit haette ich niemals gerechnet. Die Verhulst Verteilung erzeugt Verteilungen die eher der Buchstabenverteilung gleichen als der Zipf Verteilung ! Jede Menge Nullstellenkandidaten. Trotz Y X Q. Das gehe ich noch schnell abschnittsweise durch und dann mache ich Schluss fuer heute :-)   Vor und nach dem grossen Fenster der Ordnung   Argh ... da sind ja ueberall Nullstellenkandidaten. Ich meine aber wie gehabt : The Winner ist der Bereich vor und nach dem grossen Fenster der Ordnung. Ge?ndert von richy (31.08.10 um 05:06 Uhr) 
|
|
#12
31.08.10, 04:04
|
||||
|
||||
|
Diese Uebereinstimmung der Buchstabenverteilung mit der logistischen Gleichung, diese vielen Nullstellen. Das darf doch eigentlich gar nicht wahr sein. Hab ich mich verrechnet ? Oder ein Programmierfehler ?
NEIN : Beispiel eines Verteilungsvergleiches hinter dem grossen Fenster :  rot = Buchstabenverteilung gruen= von Verhulst erzeugte Verteilung Das ist verblueffend. Nochmals der Vergleich zwischen Zipf und Buchstabenverteilung :  Sehr viel schlechter. Und dennoch spricht man von etwa Zipf verteilten Buchstabenverteilungen. Zipf ist eben nur eine Idealisierung. Real kommen die Verhulst Verteilungen den konkreten in der Praxis auftretenden Verteilungen weitaus naher. Das zeigen auch ganz drastisch alle meine letzten Schaubilder. Die Verhulst Gleichung erzeugt selbstverstaendlich auch Gleichverteilungen. Ebenso die idealisierte Zipf Verteilung. Wie sieht es aus mit Gauss Verteilungen ? Ist das gar ein universeller Generator fuer Verteilungen ? Ge?ndert von richy (01.09.10 um 15:20 Uhr)
|
|
#13
31.08.10, 08:19
|
|||
|
|||
|
Hallo Richy...
Kann es sein, das die Verhulst Gleichung und die Zipf-Verteilung einfach die "komplementären" Seiten ein und der selben Geschichte sein könnten?? Das Ideal als Theorie und die Praxis in Form der jeweils wirklich angetroffenen Verteilung? JGC
|
|
#14
31.08.10, 18:45
|
||||
|
||||
|
Hi JGC
Zitat:
Ideal Zipf verteilt ist die Verhulst Gleichung wahrscheinlich nur kurz vor dem grossen Fenster. Ansonsten produziert die Gleichung angenaehert 1/k Verteilungen die eher der angenaeherten Buchstabenverteilung einer Sprache entsprechen. Und dahinter liegt ein gemeinsames Prinzip. Wenn man Zipf die 1/k Verteilung und 1/f Leistungsdichtespektren vergleicht muss man wahrscheinlich den Aspekt des "komplementaeren" hinzufuegen. Die Zipf Verteilung laesst sich wie 1/f Spektren bisher nicht genau erklaeren. Aber man kann schon Aussagen treffen, dass diese aus einem ergonomischen Prinzip basieren. Wenn ein unbegrenzt breiter Uebertragungs oder Informationskanal zu Verfuegung steht, dann verteilt man die Leistungsdichte am guenstigsten logarithmisch ueber die Frequenzbaender. Ich bin das an anderer Stelle im Forum schon mal recht genau mit vielen Beispielen durchgegangen. Die Frage wie 1/k sowie 1/f konkret in einem Zusammenhang stehen konnte ich leider bis heute nicht loesen. Klassenverteilung und Spektren sind zwei paar Stiefel. Ich bin mir aber sicher, dass ein Zusammenhang existiert. Der Begriff "komplementaer" koennte dabei eine Rolle spielen. Gruesse Ge?ndert von richy (31.08.10 um 19:54 Uhr)
|
|
#15
01.09.10, 17:12
|
||||
|
||||
|
Das laengste deutsche Wort das mein Plapperautomat bisher erzeugt hat ist uebrigends die "Hasenrente"
Wer Mr. Zake oder Durod Gake ist weiss ich nicht so genau :-) Die Saetze sind ueberhaupt seltsam :-) EiLEFURZNEinEiLEMRZAKEinEinEi EiLE FURZ NEin EiLE MR ZAKE in Ein Ei (Das Leerzeichen habe ich noch nicht im Griff) Noch kurz zur Programmiertechnik : ************************** Im Syntheseteil, der Spracherzeugung, soll der erzeugte Verhulst Wert einen Buchstaben erzeugen, dessen Wahrscheinlichkeit dem erzeugten Verhulst Wert entspricht. Wobei sich letztere Verteilung staendig aendert. Das laesst sich recht elegant und ohne if Anweisungen implementieren. Zuerst lege ich eine primitive Index Tabelle an, die mir spaeter anzeigen wird in welcher Form die Indizes fuer das Histogramm vertauscht wurden. (Diese primitive Tabelle muss man jedesmal innerhalb der grossen r Schleife neu anlegen) > for i from 1 to N_range do index[i]:=i; od: Die primitive Tabelle : index[1]:=1; index[2]:=2; index[3]:=3; ... und so weiter Beim Erstellen des Histogrammes muss ich mir "merken" wie die Indizes vertauscht wurden. Und dies leistet die Tabelle index[] wenn ich deren Werte im Bubble Sortier Algo mit vertausche :-) > for ii from 1 to N_range-1 do > for jj from ii to N_range do > if (b[ii]<b[jj]) then > mem:=b[ii];b[ii]:=b[jj];b[jj]:=mem; > mem:=index[ii];index[ii]:=index[jj];index[jj]:=mem; > fi; > od  d: d:So geht mir die urspruengliche Information nicht verloren. Jetzt fuehre ich einen Zielindex ein um die Information direkt ansprechen zu koennen : > for ii from 1 to N_range do ziel[index[ii]]:=ii; od; Und so kann ich ohne jedliche Schleife und if Abfrage den Verhulst Wert direkt ueber eine zweifache Indizierung in das ueber die Verteilung zugeordnete Zeichen "uebersetzen"  > s:=r[v]*s*(1-s); > j:=floor(s*(N_range-1)+1); > printf(`%c`,ch[ziel[j]]); Ge?ndert von richy (02.09.10 um 17:30 Uhr)
|
|
#16
01.09.10, 20:12
|
||||
|
||||
|
Trotz der "Hasenrente" hab ich grad eine andere Idee. Wenn man die logistische Gleichung nicht allgemein fuer alle r loesen kann. Kann man vielleicht eine aehnliche nichtlineare DZGL loesen ?
http://mathworld.wolfram.com/LogisticMap.html Zitat:
Oder eine Integraltransformation bezueglich inverser Funktionen ? Ge?ndert von richy (01.09.10 um 23:53 Uhr)
|
|
#17
01.09.10, 23:04
|
||||
|
||||
|
Hi
Kann man aus der Verhulst Loesung fuer r=2 andere Loesungen generieren ? Ich meine ich bin schon fuendig geworden. Das will ich mal kurz dokumentieren. Verhulst : y(t+1)=r*y(t)*(1-y(t)) Den Ausdruck kann man umschreiben zu y(t+1)/y(t)= r*(1-y(t)) Nun betrachte ich Wolframs oder auch richies Loesung r=2 (beide von 2002) und bilde sie fuer t und t+1. Da es Funktionen sind schreibe ich y und x y:=(1/2*(1-exp((r^(t))*ln( (1-2*x) )))); y1:=(1/2*(1-exp((r^(t+1))*ln( (1-2*x) )))); (Fuer Verhulst gilt r=2) Wenn man nun den Quotienten y1/y bildet spuckt Maple nur fuer t=0 das erwartete Ergebnis aus. fuer r=2 : 2-2*x (Warum man t=0 waehlen muss ist mir noch nicht ganz klar ) Man erhaelt allgemein fuer r ein spezielles Polynom :  Variante ******* Man formt Verhulst um zu : 1-y(t+1)/(r*y(t)) = y(t) Das Loesungspolynom lautet dann :  Diese Polynome weisen natuerlich erstaunliche Eigenschaften auf. Das gehe ich morgen mal durch. Ge?ndert von richy (01.09.10 um 23:46 Uhr)
|
|
#18
02.09.10, 00:13
|
||||
|
||||
|
Somit sollte gelten :
Die analytische Loesung der Differenzengleichung : y(n+1)=y(n)*(3-6*y(n)+4*y(n)^2) lautet :  mit 3^n Ebenso y[n+1]:=y[n]*(4-12*y[n]+16*y[n]^2-8*y[n]^3); mit 4^n Es sind andere Faelle wie die einfache Verkettung der Verhulst Gleichung. Aus der chaotischen Loesung folgt nebenbei (nur fuer r=4) : -1/2*(-1+cos(2*arccos(-1+2*x)))=4*x*(1-x) Anm: Verhulst laesst sich auch darstellen als r/4-r*(x-1/2)^2 Ge?ndert von richy (02.09.10 um 18:19 Uhr)
|
|
#19
02.09.10, 18:10
|
|||
|
|||
|
Hi Richy..
Ich hab mir auch schon oft Gedanken darüber gemacht, WIE sich Sprache und deren jeweiligen möglichen Bedeutungen miteinander und ineinander Verknüpfen und entsprechend jeweils deuten lassen.. Und dabei bin ich über das Problem der "Wichtigkeit"(Bedeutungsstärke) eines in einem Wort gesprochenen Buchstabens gestoßen und der Art, WIE ein Wort, Buchstabe oder Satz gesprochen wird( langsam, schnell, von oberer Stimmlage zur tieferen Stimmlage und umgekehrt usw.... sozusagen der "Krümmungsfaktor") und bin dann zu dem Schluss gekommen, das ein "Universalübersetzer" theoretisch mit mindestens 4 (/oder gar 6) verschiedenen Parametern gleichzeitig arbeiten muss, um den Sinn einer Information in einen brauchbaren Kontex zu bringen..(2 reale Parameter und 2 imaginäre Parameter wie Wahr/unwahr/zusammenfügbar zu einer übergeordneten Bedeutung oder auch aufteilbar zu entsprechenden untergeordneten Bedeutungen, plus noch den zeitlichen Bezügen die jeweils für die zukünftigen Bedeutungen und den vergangenen Bedeutungen steten müssten, um eine "korrekte" Verbindung untereinander zu erlauben) Andererseits habe ich mir gedacht, wenn wir auf der Welt uns entschließen könnten, unsere jeweiligen Sprachen und ihre jeweiligen grammatischen Ausdrucksformen, so wie deren jeweiligen Betonungen/Sprechgeschwindigkeiten/Tonhöhen zu vereinheitlichen und zu vereinfachen, so wäre es kein Problem, auch eine Maschinensprache zu entwickeln, die universell für unsere ganze Welt gültig sein könnte und uns universell ohne Missverständlichkeiten weltweit kommunizieren lässt... Unsere jeweiligen einzelnen örtlichen Sprachen haben im Laufe der Jahrtausende viele Entwicklungen durchgemacht und sind daher sozusagen "separiert/spezialisiert" worden, obwohl letztlich überall der selbe "Senf" gequasselt wird. Selbst die Vögel unterhalten sich auch nur darüber, wer Feind und wer Freund ist, WO es das beste Futter gibt, wer wen "vögeln" darf und wer Buh und Bäh gemacht hat.. Letztlich geht jegliche Art von Kommunikation also immer um Ein und das Selbe!! Und der ganze Zweck der Geschichte liegt scheinbar darin begründet, immer ein intellektuelles, geistiges und emotionales Gleichgewicht untereinander zu schaffen, um ein harmonisches Zusammenspiel zu gewährleisten. Ein natürliches Bestreben sozusagen.. Ein Naturgesetz?? Gruß....................JGC Ge?ndert von JGC (02.09.10 um 18:13 Uhr)
|
|
#20
03.09.10, 15:50
|
|||||
|
|||||
|
Hi JGC
Zitat:
Ebenso verhaelt es sich mit den Wortlaengen : http://de.wikipedia.org/wiki/Gesetz_...ortl%C3%A4ngen Zitat:
Man muss dabei in Betracht ziehen, dass sich Woerter und Sprache in einem Entwicklungsprozess ergeben haben. Unter Aspekten der Ergonomie. Und dieser verlief fuer verschiedene Kulturen aehnlich, aber nicht gleich. Das ist ein recht faszinierende Angelegenheit. Die sich auch in der Worthaeufigkeit widerspiegelt : http://de.wikipedia.org/wiki/Liste_d...tschen_Sprache Und wenn man wollte koennte man diesen Prozess noch besser verstehen. Wenn man noch genauer statistisch, linguistisch untersuchen wuerde wie Kinder eine Sprache lernen. Dass man also nicht nur Texte der FAZ auswertet sondern systematisch die Sprache und Texte von Kindern verschiedener Altersstufen. Von 0 ab. Auch verschiedener Nationen und Phonemen. Waere sicherlich interessant. Ah das ist ja interessant : Zitat:
Und meine Idee gibt es schon : http://de.wikipedia.org/wiki/Spracherwerb Ein Beispiel : Zitat:
Vom Programm erzeugt : 2 er Zyklus : Ei Ei Ei Ei Ei Ei Ei Ei Ei Ei Ei Ei Ei Ei 4 er Zyklus : Eins Eins Eins Eins Eins Eins Eins Eins 8 er Zyklus : EinREisA EinREisA EinREisA EinREisA EinREisA auf dem Weg ins Chaos : insLiRACEDEUEnsHiRACEDEDEDEUEnsHiRATEnEUinsTinsLiRATinsLiRACEDEDEDEDEDEULiRATEDEU schon erstaunlich nicht :-) ? Die Gleichung durchlauft mit ihrer Periodenverdoppelung einen aehnlichen Prozess wie beim Erlernen einer Sprache. Aber das ist wohl auch schon alles. Dein Argument mit dem Stimmmelodie trifft zu. Auch auf die Betonung der ersten oder zweiten Silbe kommt es an. Wir haben unsere Sprache im Prinzip gar nicht systematisch erlernt sondern aus der Sprechsprache herausgefiltert. Zitat:
http://de.wikipedia.org/wiki/Esperanto Ach ja ein Aspekt ist noch interessant. Sprache ist ein formales System aber es enthaelt scheinbar keine Axiome. D.h. sie kann sich nicht ueber sich selbst definieren, sondern nur ueber physikalische Gegenstaende, Realationen e.t.c. .. Gruesse Ge?ndert von richy (03.09.10 um 18:32 Uhr)
|
|
| Lesezeichen |
|
|



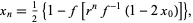





 Linear-Darstellung
Linear-Darstellung

